Background
As automated vehicles (AVs) see wider adoption in the fields of construction, warehouse management, and agriculture, it is crucial that systems are as safe as possible when interacting with pedestrians. The objective of this work was to investigate whether a stereo pair of 4K cameras can be used to accurately triangulate pedestrian 3D locations at distances of up to 100 m and whether incorporating vehicle odometry improves prediction accuracy.
Approach
Deep learning-based perception algorithms require careful dataset construction to ensure they are trained with data that is a truthful reproduction of the intended application space. We constructed a varied dataset where different real-world scenarios are accounted for, including vehicle turns, far distances and speed variations. Figure 1 highlights a sample of the data captured during the project; however, before this raw data is used to train our motion prediction model, it must be processed. First, a pedestrian detection and tracking stage is used to track pedestrians in our 4K camera feeds. Next, SwRI’s Markerless Motion Capture system (MMOCAP) is used to obtain the 3D joint locations of the tracked pedestrians. Finally, the data is collated into sequences which are used to train our prediction model.
Figure 1: Example of Processed Data.
Figure 2 describes the overall pipeline to take raw images and process them into the format needed to train and evaluate our neural network. Once the data has been collected, the data is automatically labeled and assigned to either our training or evaluation datasets. Finally, these datasets are used to train a neural network which can accurately predict the future 3D location of pedestrians.
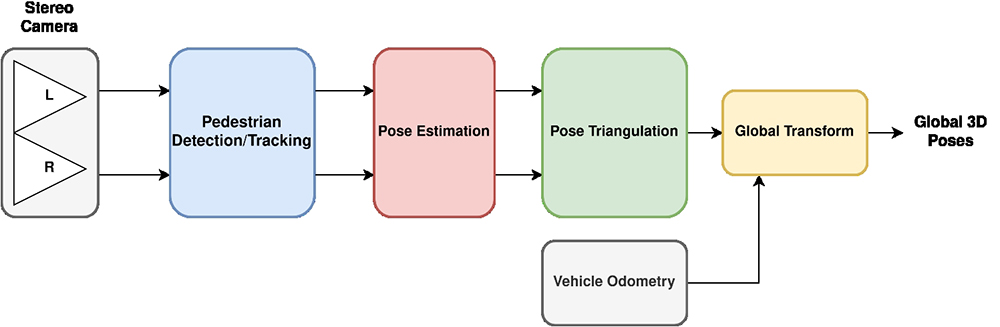
Figure 2: Data Processing Pipeline Diagram.
Accomplishments
We have constructed our data collection test bed consisting of a stereo pair of 4K cameras as well as an NVIDIA AGX. Additionally, we constructed the data processing pipeline in its entirety and processed data captured at several locations on SwRI’s campus. After creating our full dataset, we upgraded our underlying motion prediction model to operate using 3D data rather than 2D data. A custom architecture was designed to better take advantage of fine-grain spatial and temporal features. This network was trained using our training set and evaluated using our reserved test set. Figure 3 depicts an example of the performance of the pedestrian prediction network. Even in scenarios in which the vehicle was in motion, the system produced accurate predictions of pedestrian motion. As a step towards the goal of understanding human motion in an operational environment, the results of this effort have shown that it is possible for true 3D pedestrian motion to be predicted.

Figure 3: Pedestrian Motion Prediction Example.