Submitted by Ryan Mcbee on Mon, 08/28/2023
Computing in space tends to be constrained by the size, weight, power and cost of radiation-hardened systems that can fit on spacecraft. Historically, these constraints have ruled out deployment of machine learning (ML) and artificial intelligence (AI) applications, which require substantial memory and power to automate image detection and other tasks.
Recent advancements in space-ready processors are ushering in a new frontier in AI space research, enabling novel mathematics and computing that can be reconfigured to compress and process data more efficiently.
This article discusses how a novel method of training machine learning algorithms helped to reduce the bits required in the computations. This Southwest Research Institute lab research used a space-ready field programmable gate array (FPGA) to enable low-precision mathematics that would not have been possible with a traditional CPU or GPU. The solution leveraged an open-source YOLO algorithm (you only look once) deployed to an FPGA and outperformed a commercially available YOLO-FPGA deployment.
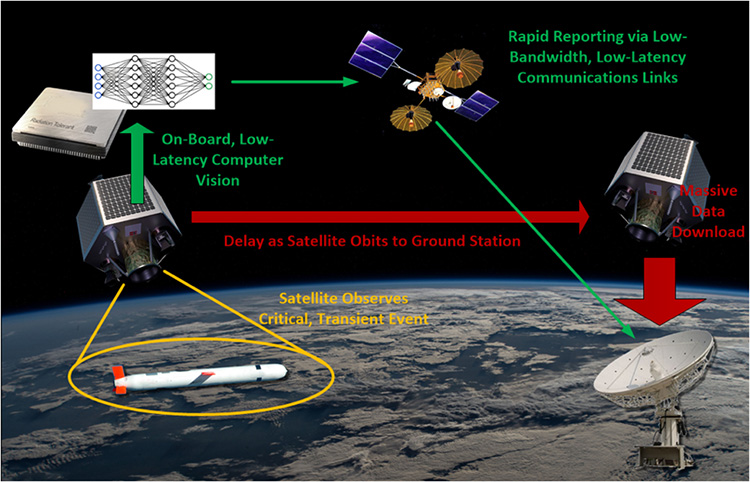
This image depicts how a field programmable gate array (FPGA) onboard a satellite can more effectively process a machine learning algorithm using low-precision mathematics.
Configuring FPGAs to run Deep Neural Networks in Space
The demands of an ML object-detection algorithm powered by a deep neural network (DNN) surpass the available resources of traditional computers and power systems requiring more specialized and larger system to run in real time. Transitioning to new computational hardware can create more opportunities to integrate DNNs into applications for spacecraft, unmanned aerial systems (UAS) and remote sensing using machine vision technology. DNNs can also enable responses to incoming data without a communication link to remote hardware. This is important when satellite communications are often intermittent.
Current DNNs use eight bits of information to represent each of the millions of numbers used in the mathematical computation. A low-precision formulation using four or fewer bits can drastically reduce the memory and computation requirements enabling deployment on more limited computing platforms but results in dramatically reduced accuracy when trained using normal machine learning techniques. A team of SwRI researchers investigated how to reduce this decrease in accuracy and better understand the trade-off between speed and accuracy when deployed on an FPGA, which is a configurable integrated circuit that can effectively use low precision mathematics.
Low-Precision Mathematics for Novel Data Training
We explored using n-bit mathematics, with n varying between 2-4 bits to train a convolutional neural network (CNN) object detector on the visual object classes (VOC) dataset, with an example image from the VOC dataset shown below. Training a CNN with low-precision using traditional machine learning techniques results in dramatically reduced accuracy. This is clear when you realize that a traditional 8-bit number can be any of 256 values, while a 2-bit value can only represent a total of 4 values. This extreme decrease in expressiveness required the team to rethink the training process to account for this decreased mathematical precision and create novel training techniques.
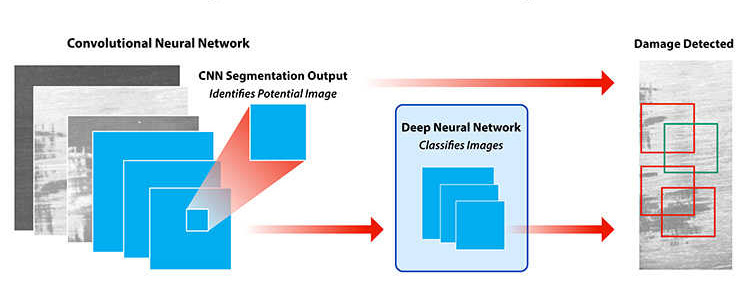
A convolutional neural network (CNN) identified potential damage to regions within an image. The CNN algorithm was trained by comparing monochrome images under varying lighting. A secondary deep neural network classified monochrome images as containing damage (or not) based on feature values produced by the CNN.
The uniqueness of the low-precision math makes machine learning unable to be efficiently to ran on a traditional CPU or GPU, but FPGAs are highly configurable and have support for arbitrary precision of computation making it an ideal platform for deploying our low precision. The team took advantage of an open-source framework to quickly deploy the algorithm to a commercially available FPGA and explore various resource and accuracy trade-offs for our design.
FPGAs are different from normal CPUs and GPUs in that you reconfigure the FPGA to become your algorithm, and these algorithms are implemented using a finite number of resources on the FPGA. Using less resources enables more copies of that algorithm to be implemented or enables other algorithms to be deployed on the FPGA.
Speed vs Accuracy in YOLO Algorithm Research
The results from our project are shown in the table below. This table shows that our design can be roughly two times faster, uses roughly half of the Look Up Table (LUT) and Block RAM (BRAM) resources, and uses zero digital signal processing (DSP) resources compared to the commercially available machine learning on FPGA using a common YOLOv3 (you only look once 3) object-detection algorithm. The main drawback in our low-precision implementation is the decreased accuracy, which the team hopes to address in the coming year through better training techniques.
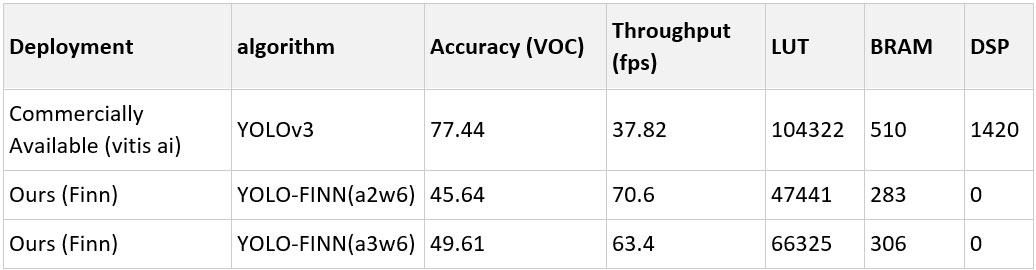
This table compares an SwRI-developed and trained YOLO algorithm to a commercially available YOLO algorithm. Both the SwRI and the commercial algorithms were deployed to an FPGA computer. The SwRI algorithm is faster and uses less computational power and memory.
Through our experience in inventing, experimenting, developing, testing and evaluating advanced algorithms and applications on FPGAs, our team has all the right tools to help you determine if an FPGA approach is a good match for your application. It’s not always trivial transitioning from traditional compute hardware to an FPGA solution and having us on board to help can get your project to the finish line faster. Contact Ryan McBee to discuss your project needs and how we can help develop advanced algorithms or space computing solutions.
