
Background
SwRI often faces the challenge of leveraging the intellectual property (IP) left behind by employees who depart or advance within the Institute. This is particularly critical for legacy software and specialized toolsets, which can have complex and outdated code structures, limited documentation, and are maintained by small teams of domain experts rather than professional software engineers. Large language models (LLMs) offer a potential solution for preserving institutional knowledge in legacy software development given their ability to process large amounts of text data and contextualize information for specific applications.
A previous LAMP Phase A project developed an LLM digital assistant, REMNANT, that could help non-software engineers maintain and transfer SwRI’s software code CENTAUR (Collection of ENgineering Tools for Analyzing Uncertainty and Reliability) which has not been under active development. Two key accomplishments that REMNANT enabled during the Phase A project were: (1) compiling CENTAUR and CENTAUR’s Python API for the first time in four years and (2) prompt-tuning the LLM to be able to generate accurate scripts to interface with CENTAUR’s Python API. However, due to token limitations, the Phase A solution could not access the entire code repository, and the tool was not capable of supporting software advancement (e.g., implementation of new algorithms and methods in the code) without more strategic content management algorithms.
Building on the successes of the LAMP Phase A project, this Phase B project aims to further extend the capabilities of LLMs at SwRI and address limitations identified in supporting legacy software maintenance and development. The main focus areas of this Phase B project are context management, software advancement, and extension to other legacy software tools.
Approach
This LAMP Phase B project has explored enhancing REMNANT with code assistant tools that both automate context generation and can be accessed within widely-used integrated development environments (IDEs) like Visual Studio (VS) Code. These code assistant tools are referred to as LLM scaffolds because they are generally LLM-agnostic, meaning that the integrated software development features and logic that makes additional calls to the LLM from user queries are not specific to a particular LLM. Important requirements for a viable LLM scaffold are that it maintains the privacy of proprietary data, allows for full control over the context management approach, and can include multiple context types. Two open-source LLM scaffolds, Cline and Continue, have been investigated during this phase. Cline and Continue are offered as extensions for VS code and interface with the FedRAMP-certified instance of GPT-4o hosted by Microsoft Azure and available to SwRI employees. Both of these tools meet the security and flexibility requirements for ingesting proprietary legacy software code bases.
To address context management challenges identified in Phase A, this Phase B effort is investigating approaches such as retrieval-augmented generation (RAG) and knowledge graphs to enhance the LLM’s ability to comprehend and interact with the full code base and repository of legacy software tools. These context management approaches are being evaluated separately, and then final, optimized versions of the RAG and knowledge graph are being integrated with an LLM scaffold for use within the IDE. This means that the user will have access to all of the tools – the LLM, the LLM scaffold (Cline or Continue), the knowledge graph, and RAG - within one environment.
Evaluations are being performed to test the effectiveness of the tools with technology transfer, code identification, and code advancement. Responses are being manually graded according to accuracy and/or usefulness of the response. A code advancement demonstration problem has also been developed to showcase the capabilities of the tools developed and leveraged during this Phase B project.
Accomplishments
During this effort, RAGs and knowledge graphs have been developed for multiple software tools: CENTAUR, NESSUS (Numerical Evaluation of Stochastic Structures Under Stress), and the NESSUS graphical user interface (GUI). These tools have helped to provide a better understanding of the code structure and make the repositories and Git commit logs searchable by the LLM. Figure 1 shows an example of searching the CENTAUR knowledge graph to reveal the nodes and edges associated with a function named “gptest”. Nodes in the knowledge graphs developed in this study can be a function or filename, and edges describe the relationships between the nodes.
Evaluations with tools developed during this Phase B effort show a significant improvement in code identification compared to the Phase A effort. Figure 2 shows an illustration of CENTAUR’s code structure and the results of the code identification evaluations related to the CENTAUR. The latest version of the RAG model (RAGv2), which has access to the Git commit logs and the Git file tree, has shown improved responses over previous versions and tools. Note that the Phase A results relied on manual prompt-tuning by the user, and token limits prevented prompt-tuning with all of the CENTAUR source code. After evaluating several vector databases for the RAG, we have settled on using ElasticSearch due to its ability to perform hybrid queries, blending semantic search through vectors with traditional keyword searches.
The Phase A results showed that the LLM digital assistant, REMNANT, excelled at Python script generation, achieving over 80% accuracy in creating Python scripts for CENTAUR technology transfer. So far, the Phase B testing has shown that the new LLM software development tools do not significantly improve on the Phase A results. However, the new LLM tools make it much easier to include context in the prompt, which was a limitation of the Phase A effort.
In addition, in Phase B two engineers with little to no experience compiling software used the LLM to compile the CENTAUR and the Python bindings in Python versions 3.7 through 3.13. This was a significant accomplishment because before this program, the CENTAUR Python API was only available up to Python 3.7 and only the lead developer knew how to compile the software.
Finally, the LLM software development tools are currently being used to help implement a new feature into the CENTAUR source code. This effort is being performed to demonstrate the utility of using the LLM tools to advance the software, as opposed to just maintaining the software and transferring the technology.
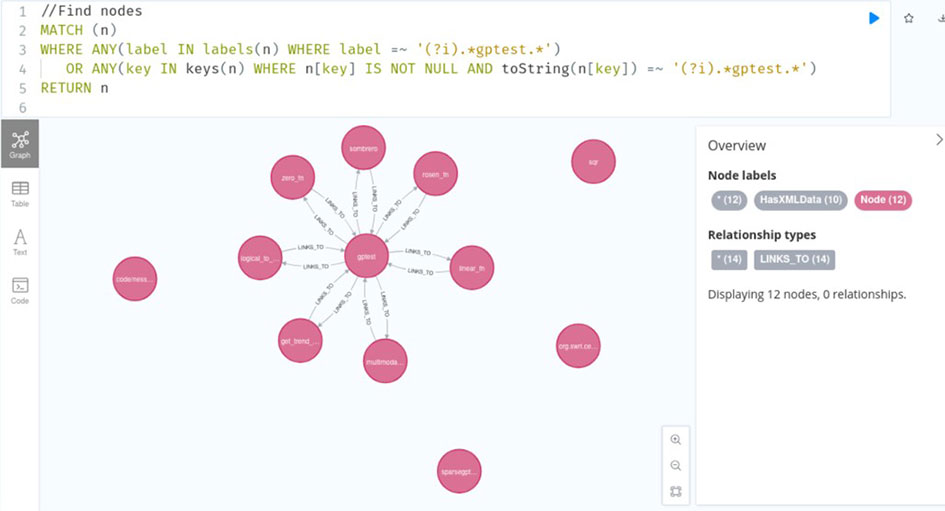
Figure 1. Example CENTAUR knowledge graph search revealing the nodes and edges associated with a function named “gptest”.
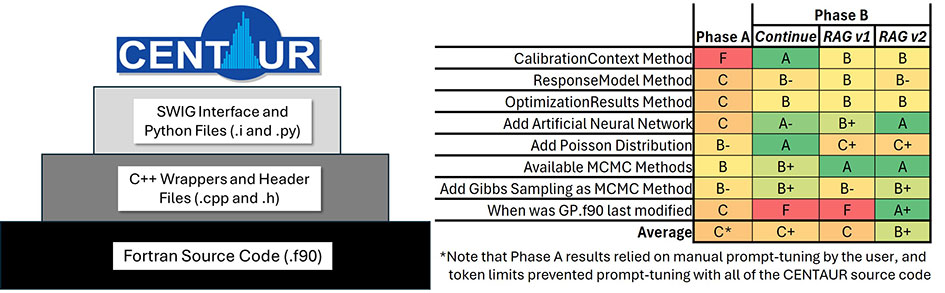
Figure 2. Illustration of CENTAUR’s code structure (left) and summary of code identification testing (right).